



As a kid, cloud monitoring meant going outside and looking for new shapes created by clouds in the sky. If only it was that simple for network engineers today.
Now, many organizations begin and end monitoring cloud services with a ping test: “ping the server and see if it responds”.
The problem with relying only on the ping test for cloud monitoring is that users hold network professionals to high standards on all components of a data network.The network engineers need to be able to identify when problems occur, who is responsible, troubleshoot the problems, as well as initiate fixes and avoid reoccurances.
This means that engineers need a different way to monitor the performance of cloud services.
What's Different with Cloud Services?
Cloud services tend to add a lot of complexity to the picture, as more players are involved with providing the services. In addition, standard monitoring tools are mostly ineffective at showing the complete picture since they are designed to monitor on-premise servers and services and don't know the difference.
Where Can Cloud Service Problems Occur?
Here are the locations where problems can occur:
- Your own network: Any packet loss or buffering occurring inside of your own network can cause slowdowns and disconnects.
- Your ISP: If ISPs are dropping or buffering packets, access to all of your cloud services may be affected.
- An Internet backbone provider: This means that the entire Internet may be affected by this problem.
- The cloud service provider's network: The cloud service provider rarely likes to admit or expose the fact that they caused the problem, but this can frequently occur.
What Problems Can Occur with Cloud Services?
Users will complain about one of two problems that occur when trying to access cloud services:
- Slowdowns: This is typically the biggest complaint, as users get frustrated when they don't get snappy responses from their cloud services.
- Disconnects: If problems persist or get worse, users will get dropped from their cloud servers and have to login again.
What Causes These Problems to Happen?
These problems frequently occur due to one primary reason: packet loss.
If a file download typically takes 10 seconds under normal circumstances, but there is 20% packet loss, then it will take more than 12 seconds at a minimum to transfer the data.
Why more? TCP/IP includes a "backoff" mechanism that will slow down sending if it detects loss. This mechanism is designed to prevent links and devices from becoming completely flooded when there is a lot of utilization.
| Note: | More information on TCP's sliding windows protocol and the backoff mechanism is available here: Wikipedia: Sliding Window Protocol |
If the latency is high for this conversation (over 100ms), then the backoff mechanism will add addiitonal delay to transfer the entire file.
The result is that a normal 10 second download might end up being 20 seconds when there is loss.
| Note: | Newer operating systems and programs may support the TCP Fast Open mechanism that will help more rapidly recover from packet loss conditions. (See Wikipedia: TCP Fast Open) |
Is Latency or Jitter a Concern for Cloud Services?
Most cloud services rely on TCP/IP connections. TCP communications are mostly unaffected by jitter and out-of-order packets, as they are all reassembled correctly at the destination.
Normally, latency has only a slight effect on TCP communications, increasing the delay for packet arrival and acknowledgements. This delay may be worsened when packet loss occurs as described in the previous section.
| Note: | If the cloud service involves real-time protocols like VoIP, UC, and video, then latency, jitter, and out-of-order packets will affect communications quality. Refer to our blog entries on latency, jitter, and out-of-order packets. |
What Causes Packet Loss to Happen to Cloud Services?
Packets can be lost on their way to or from a cloud service for several reasons:
- Link congestion
- Route flaps
How Do You Troubleshoot Cloud Services?
A lot of different elements need to be tracked to be able to troubleshoot cloud service problems:
- Is the cloud service reachable? This can be done via a simple ping or web request to determine if the remote-end server and service are responding.
- Did any route changes occur? If things were good, then bad, then good again, what changed on the way to the cloud? If a route changed for a few minutes, you should know this. This can be done manually via a continuous traceroute, or with a cloud service monitoring system like PathSolutions TotalView.
- What was the route path at the time of the quality problem? You will want to know which routers were used at that timepoint.
- Did any problems occur along that path? Was there any loss, latency, or jitter that occurred, and where did it occur?
- Which router made the route change that caused the problem? If you can determine which router made the change, you can recognize who is responsible for that router and contact them for troubleshooting follow-up.
Consider the following route-tree diagram:
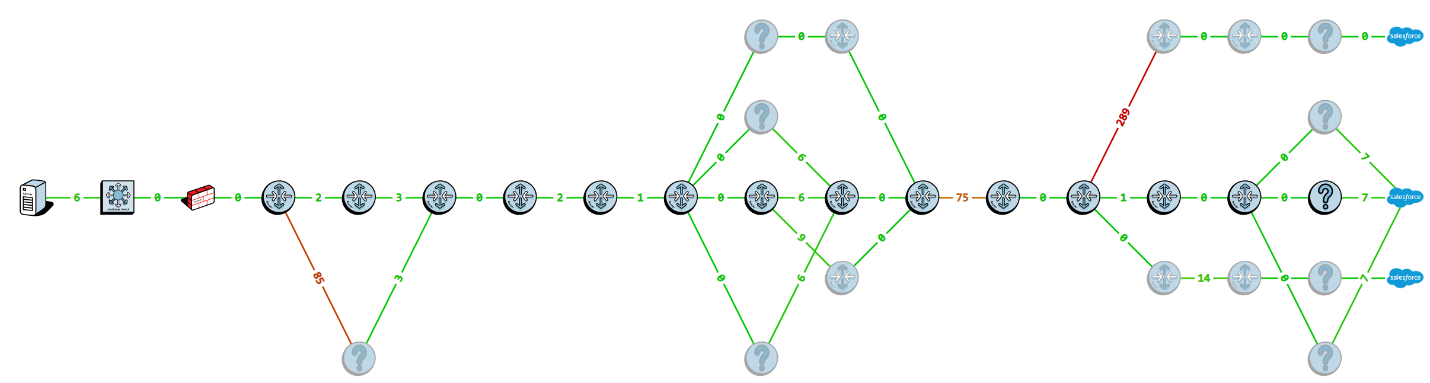
The device on the left side of the route-tree is the computer where testing was initiated. The first two devices beyond that are internal to the corporate network.
The next few routers are managed by the company's ISP.
The center hops are part of the Internet backbone.
Towards the top right side, we see a link with really high latency branching to a cloud server inside of Salesforce.com.
If we hover over that router, it shows that 32 minutes ago this was the path taken, and that the router is part of Salesforce's network:
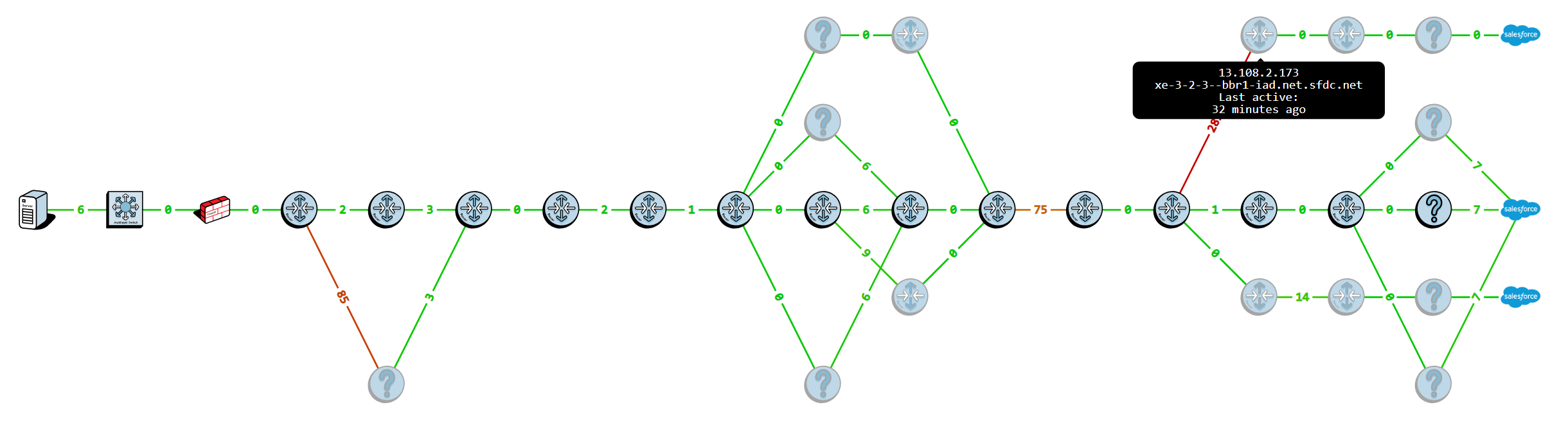
We can then hover over the router that made the route change to see who owns/manages that router:
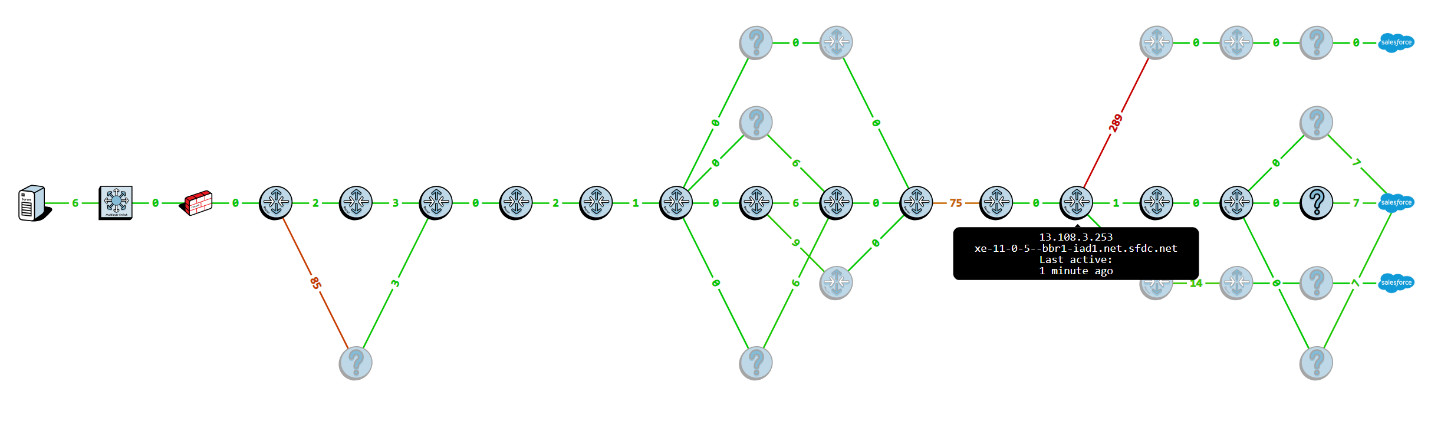
In this case, this router is also part of Salesforce's network.
If we contact the Salesforce.com support desk, we learn that 32 minutes ago this router sent traffic to a datacenter across the Pacific due to an outage in their network.
Overall, loss can be prevented if the right information is brought to bear about your network's performance.
Contact us with questions about how PathSolutions TotalView can solve cloud service issues.





