 Imagine you are investigating the scene of a murder. After spending an entire day combing for evidence, you and your team can only find three small clues as to who the culprit could be — meaning you don’t have enough information to help you get to the bottom of the case. It could take years to find out the truth.
Imagine you are investigating the scene of a murder. After spending an entire day combing for evidence, you and your team can only find three small clues as to who the culprit could be — meaning you don’t have enough information to help you get to the bottom of the case. It could take years to find out the truth.
Now, suppose you had an automated clue-collector that found 50 clues and an analytical computer to stitch the pieces together. You could probably wrap up the case in just a few minutes.
We can apply this same thought to network troubleshooting, where we are often tasked with discovering network errors, interpreting them and piecing them together to fix a problem and move forward. If you had access to all of the clues, and a CSI-Like analytical computer, the root-cause problem would be easy to determine.
Many companies, though, are still investigating issues the old-fashioned way, using tools that provide only partial visibility into the network and thus incomplete answers. And so in this series, we’re going to show you some examples of what this process looks like when you do it manually.
Here’s our first case:
A while back, we had a large, Fortune 500 cosmetics firm who had call quality issues on their network. The company was using Microsoft Skype for Business to support a number of locations around the world with VoIP. But every time a caller would join after a call started, or video was added during a call, the call would drop.
This customer spent a great deal of time searching through the network to find out what was happening, but could not locate the root cause.
The customer had only a few clues to work with:
- They knew that since call quality was suffering, there were glitches on the network related to packet loss. However, they didn’t know where the packet loss was occurring or why.
- Their network monitoring software indicated that “everything was fine.”
- The MPLS provider insisted that everything was fine with their cloud, and QoS was properly deployed.
What’s more, the network was very large and contained many links, switches and routers. So they knew the problem could be happening at any one of these points, but it wasn’t clear where.
And finally, the company was working with multiple service providers, meaning any one of them could be responsible.
Put yourself in the shoes of an engineer running into this problem. There’s barely even enough information here to make a guess at the root cause of the problem.
Take a few minutes to think this through. Can you come up with any possible solutions? (And blindly blaming the WAN provider is a wild stab in the dark.)

Problem Solved: The TotalView Drill-Down
Our customer contacted PathSolutions to help solve the problem. After spending a few minutes assessing the network, a light bulb suddenly went off. We turned our attention to the customer’s QoS queues.
Our customer then deployed TotalView, which is our fully-automated network troubleshooting platform, to drill down into their QoS queue configurations. And within a few minutes, the customer was able to gather enough information to discover hard confirmation that their MPLS WAN router had the VoIP queue configured with the wrong DSCP match condition.
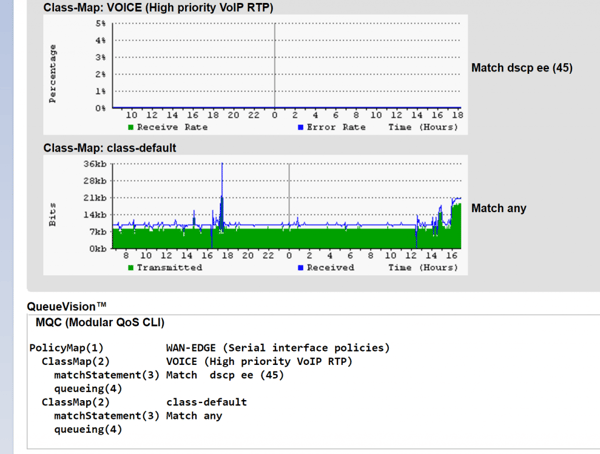
Why was this causing VoIP performance issues? It’s simple: In order for clear and reliable VoIP calls to take place, data packets need to flow efficiently through the network. When a device has a misconfigured QoS queue, it looks a bit like a crowded toll booth plaza during rush hour where there are open express lanes that cars don’t know about. As such, some lanes have too much traffic and some lanes have too little. Therefore, a traffic jam occurs which negatively impacts communication.
Adding to the challenge is the fact that network and telecom teams don’t always have visibility into their QoS queues — especially if they are using carrier-issued MPLS routers and WAN links. Troubleshooting this problem typically requires manually entering commands into the CLI and then interpreting raw data. Most network administrators don’t even think to look at the QoS queue when performance issues arise.
In this case, our customer simply had to look into their QoS queue configurations using TotalView. Then, they called their MPLS provider and show them the facts that QoS configurations were wrong on their edge routers. Call quality was noticeably improved as a result.
The MPLS provider was as much in the dark as the customer about the misconfigured queue, but that’s sadly a normal occurrence. You typically have to prove that there is a fault in the queue, and then provide enough evidence for them to go and check.
It’s safe to say they would still be searching for the problem without the help of our automated root-cause troubleshooting solution. In fact, they may never have gotten to the bottom of the issue! The case could have been marked as “unsolved,” meaning the enterprise would have continued suffering from call quality without ever discovering why.
Read part two of this series, where we present another network troubleshooting mystery!





